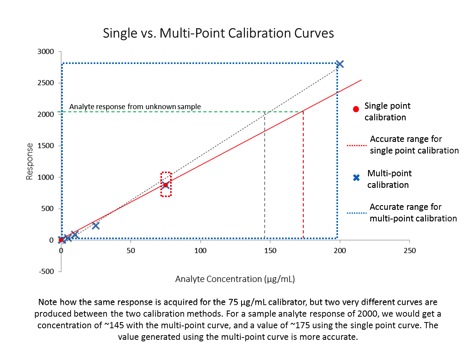
Despite the title, this article is not about weight loss – it is about generating valid analytical data for quantitative analyses. In the last installment of The Practical Chemist, I introduced instrument calibration and covered a few ways we can calibrate our instruments. Just because we have run several standards across a range of concentrations and plotted a curve using the resulting data, it does not mean our curve accurately represents our instrument’s response across that concentration range. In order to be able to claim that our calibration curve accurately represents our instrument response, we have to take a look at a couple of quality indicators for our curve data:
- correlation coefficient (r) or coefficient of determination (r2)
- back-calculated accuracy (reported as % error)
The r or r2 values that accompany our calibration curve are measurements of how closely our curve matches the data we have generated. The closer the values are to 1.00, the more accurately our curve represents our detector response. Generally, r values ≥0.995 and r2 values ≥ 0.990 are considered ‘good’. Figure 1 shows a few representative curves, their associated data, and r2 values (concentration and response units are arbitrary).
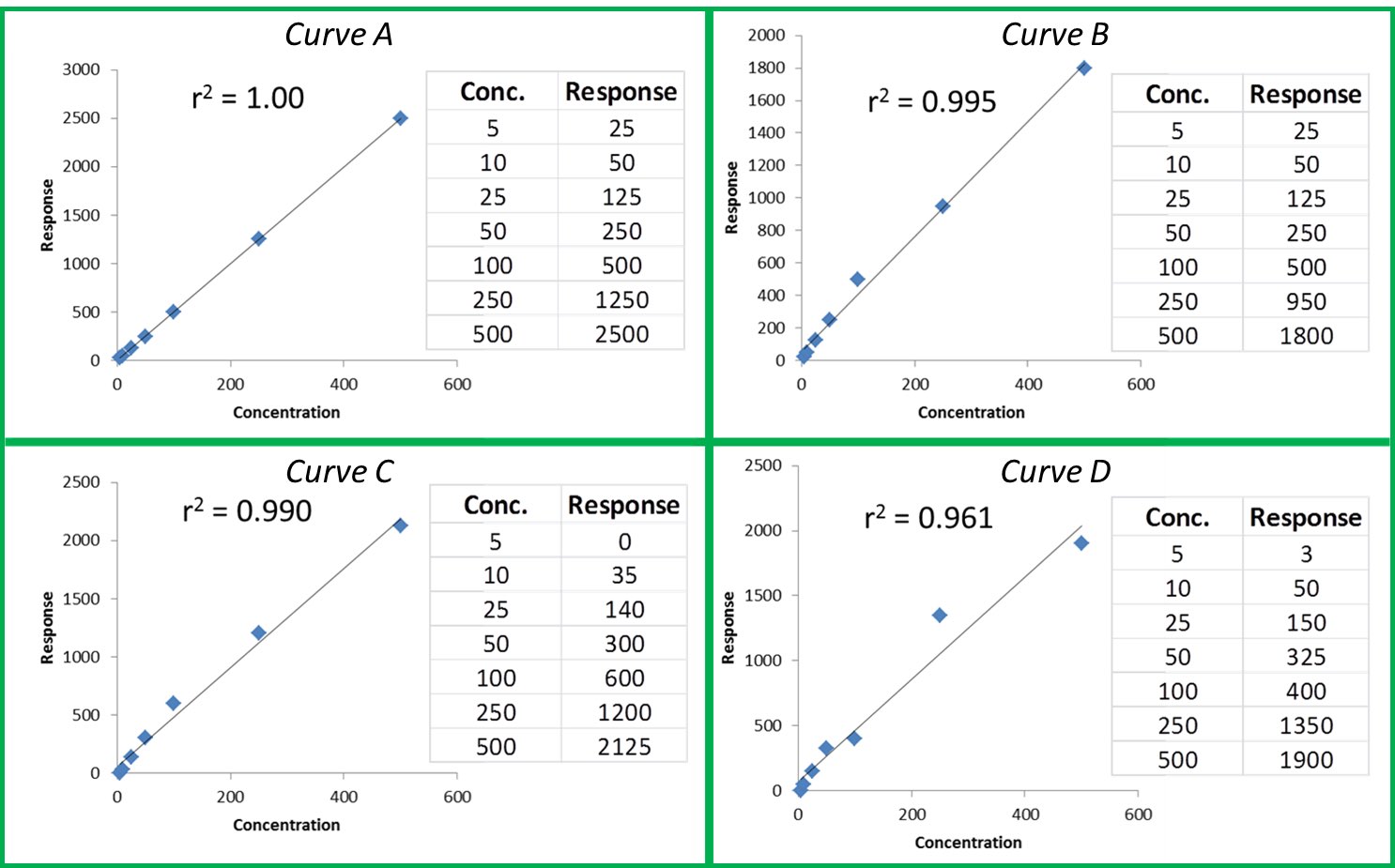
Let’s take a closer look at these curves:
Curve A: This represents a case where the curve perfectly matches the instrument data, meaning our calculated unknown values will be accurate across the entire calibration range.
Curve B: The r2 value is good and visually the curve matches most of the data points pretty well. However, if we look at our two highest calibration points, we can see that they do not match the trend for the rest of the data; the response values should be closer to 1250 and 2500. The fact that they are much lower than they should be could indicate that we are starting to overload our detector at higher calibration levels; we are putting more mass of analyte into the detector than it can reliably detect. This is a common problem when dealing with concentrated samples, so it can occur especially for potency analyses.
Curve C: We can see that although our r2 value is still okay, we are not detecting analytes as we should at the low end of our curve. In fact, at our lowest calibration level, the instrument is not detecting anything at all (0 response at the lowest point). This is a common problem with residual solvent and pesticide analyses where detection levels for some compounds like benzene are very low.
Curve D: It is a perfect example of our curve not representing our instrument response at all. A curve like this indicates a possible problem with the instrument or sample preparation.
So even if our curve looks good, we could be generating inaccurate results for some samples. This brings us to another measure of curve fitness: back-calculated accuracy (expressed as % error). This is an easy way to determine how accurate your results will be without performing a single additional run.
Back-calculated accuracy simply plugs the area values we obtained from our calibrators back into the calibration curve to see how well our curve will calculate these values in relation to the known value. We can do this by reprocessing our calibrators as unknowns or by hand. As an example, let’s back-calculate the concentration of our 500 level calibrator from Curve B. The formula for that curve is: y = 3.543x + 52.805. If we plug 1800 in for y and solve for x, we end up with a calculated concentration of 493. To calculate the error of our calculated value versus the true value, we can use the equation: % Error = [(calculated value – true value)/true value] * 100. This gives us a % error of -1.4%. Acceptable % error values are usually ±15 – 20% depending on analysis type. Let’s see what the % error values are for the curves shown in Figure 1.
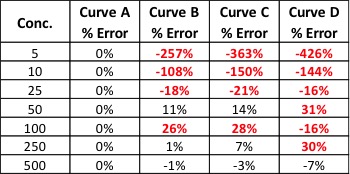
Our % error values have told us what our r2 values could not. We knew Curve D was unacceptable, but now we can see that Curves B and C will yield inaccurate results for all but the highest levels of analyte – even though the results were skewed at opposite ends of the curves.
There are many more details regarding generating calibration curves and measuring their quality that I did not have room to mention here. Hopefully, these two articles have given you some tools to use in your lab to quickly and easily improve the quality of your data. If you would like to learn more about this topic or have any questions, please don’t hesitate to contact me at amanda.rigdon@restek.com.